所有权是Rust特有的核心概念,该特性让Rust即使没有垃圾回收或引用计数等机制也能够编写出内存安全的程序。
野指针:是指向“垃圾”内存(不可用内存)的指针,指针创建时未初始化。指针变量刚被创建时不会自动成为NULL指针,它会随机指向一个内存地址。
悬垂指针(Dangling pointers): 指向无效数据的指针(当我们了解数据在内存中如何存储之后,这个就很有意义)。你可以在这里了解更多悬垂指针
胖指针(fat pointer):术语“胖指针”用于指代*动态大小类型*(DST)的引用和原始指针——切片或特征对象(The term “fat pointer” is used to refer to references and raw pointers to *dynamically sized types* (DSTs) – slices or trait objects.)
内存的堆和栈
1 | let str = "hello world".to_string(); |
“hello world” 作为一个字符串常量(string literal),在编译时被存入可执行文件的 .RODATA 段(GCC)或者 .RDATA 段(VC++),然后在程序加载时,获得一个固定的内存地址。
这个时候如果没有后面的to_string()方法,那么 str 便是一个存在栈区的指针指向作为可执行文件的一部分存储在只读内存中的预分配文本(preallocated text)
1 | s: &str |
当执行 “hello world”.to_string() 时,在堆上,一块新的内存被分配出来,并把 “hello world” 逐个字节拷贝过去。
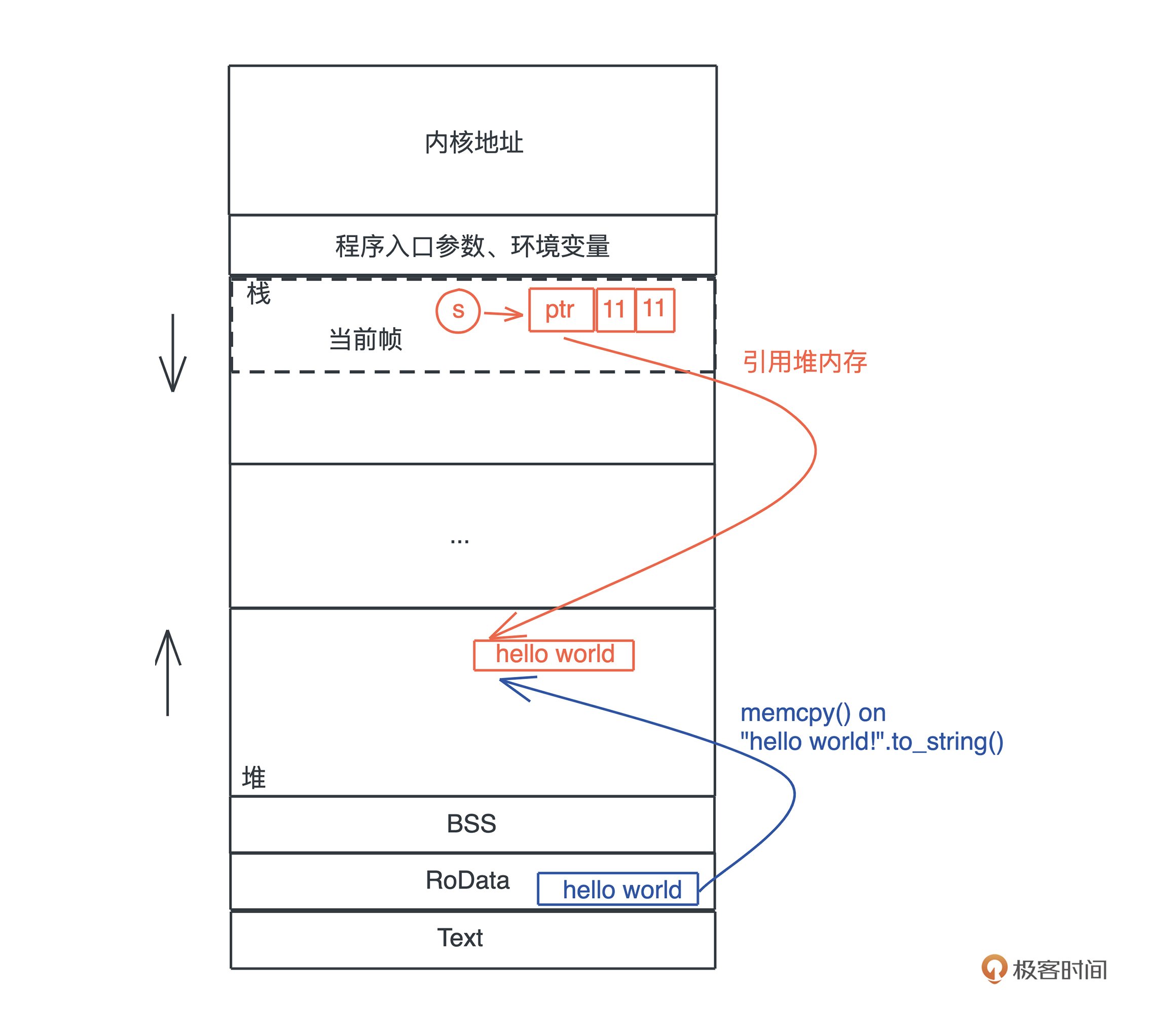
对于存入栈上的值,它的大小在编译期就需要确定。栈上存储的变量生命周期在当前调用栈的作用域内,无法跨调用栈引用。
堆可以存入大小未知或者动态伸缩的数据类型。堆上存储的变量,其生命周期从分配后开始,一直到释放时才结束,因此堆上的变量允许在多个调用栈之间引用。
但也导致堆变量的管理非常复杂,手工管理会引发很多内存安全性问题,而自动管理,无论是 GC 还是 ARC,都有性能损耗和其它问题。
一句话对比总结就是:栈上存放的数据是静态的,固定大小,固定生命周期;堆上存放的数据是动态的,不固定大小,不固定生命周期。
变量在被函数调用时发生了什么
1 |
|
动态数组因为大小在编译期无法确定,所以放在堆上,并且在栈上有一个包含了长度和容量的胖指针指向堆上的内存。
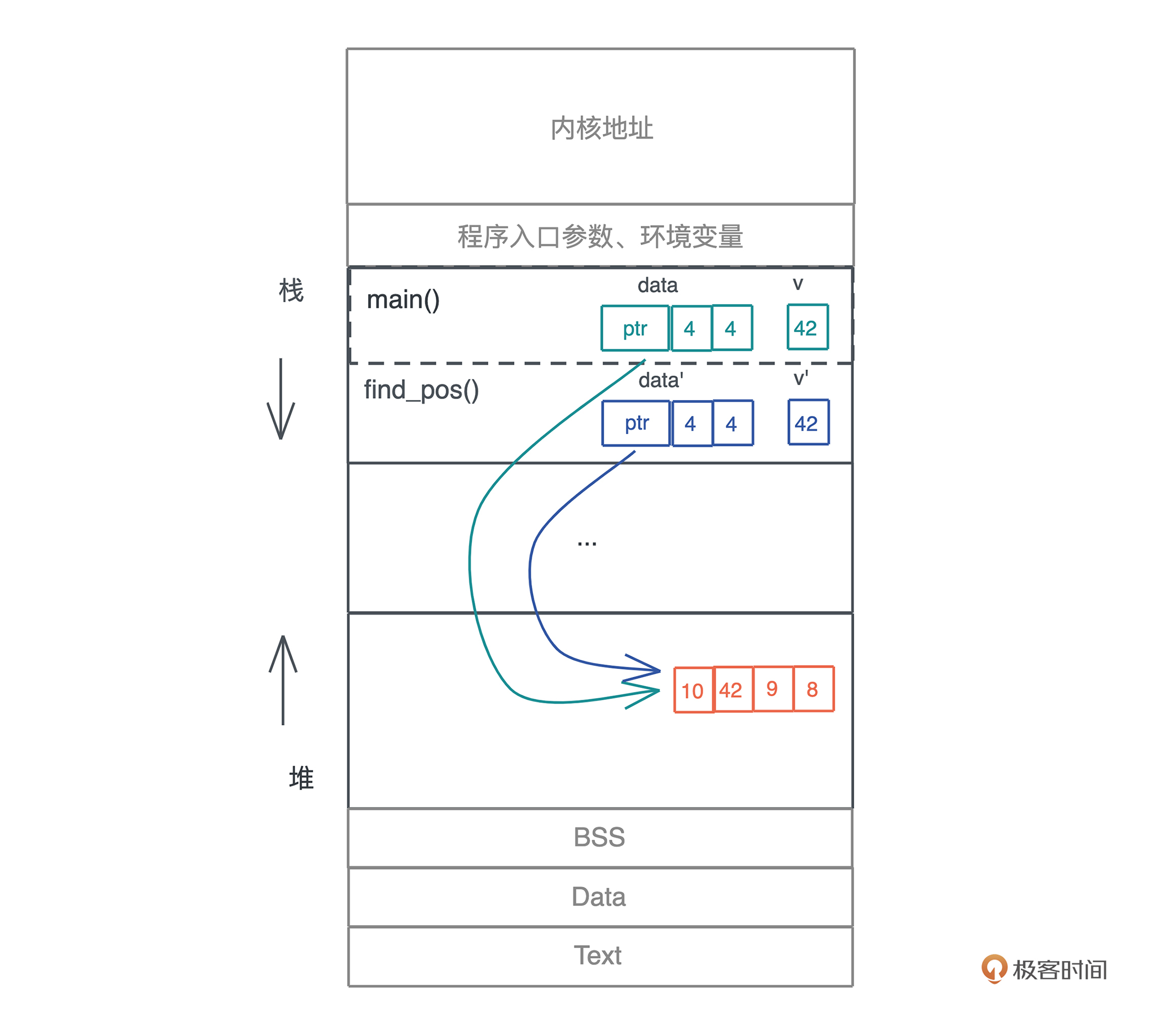
对于堆内存多次引用的问题,我们先来看大多数语言的方案:
- C/C++ 要求开发者手工处理,非常不便。这需要我们在写代码时高度自律,按照前人总结的最佳实践来操作。但人必然会犯错,一个不慎就会导致内存安全问题,要么内存泄露,要么使用已释放内存,导致程序崩溃。
- Java 等语言使用追踪式 GC,通过定期扫描堆上数据还有没有人引用,来替开发者管理堆内存,不失为一种解决之道,但 GC 带来的 STW 问题让语言的使用场景受限,性能损耗也不小。
- ObjC/Swift 使用自动引用计数(ARC),在编译时自动添加维护引用计数的代码,减轻开发者维护堆内存的负担。但同样地,它也会有不小的运行时性能损耗。
Rust 的解决思路
Rust 决定限制开发者随意引用的行为, 通过规则保证单一所有权:
- 一个值只能被一个变量所拥有,这个变量被称为所有者(Each value in Rust has a variable that’s called its owner)
- 一个值同一时刻只能有一个所有者(There can only be one owner at a time)
- 当所有者离开作用域,其拥有的值被丢弃(When the owner goes out of scope, the value will be dropped)
所以上面的问题变成了这样:
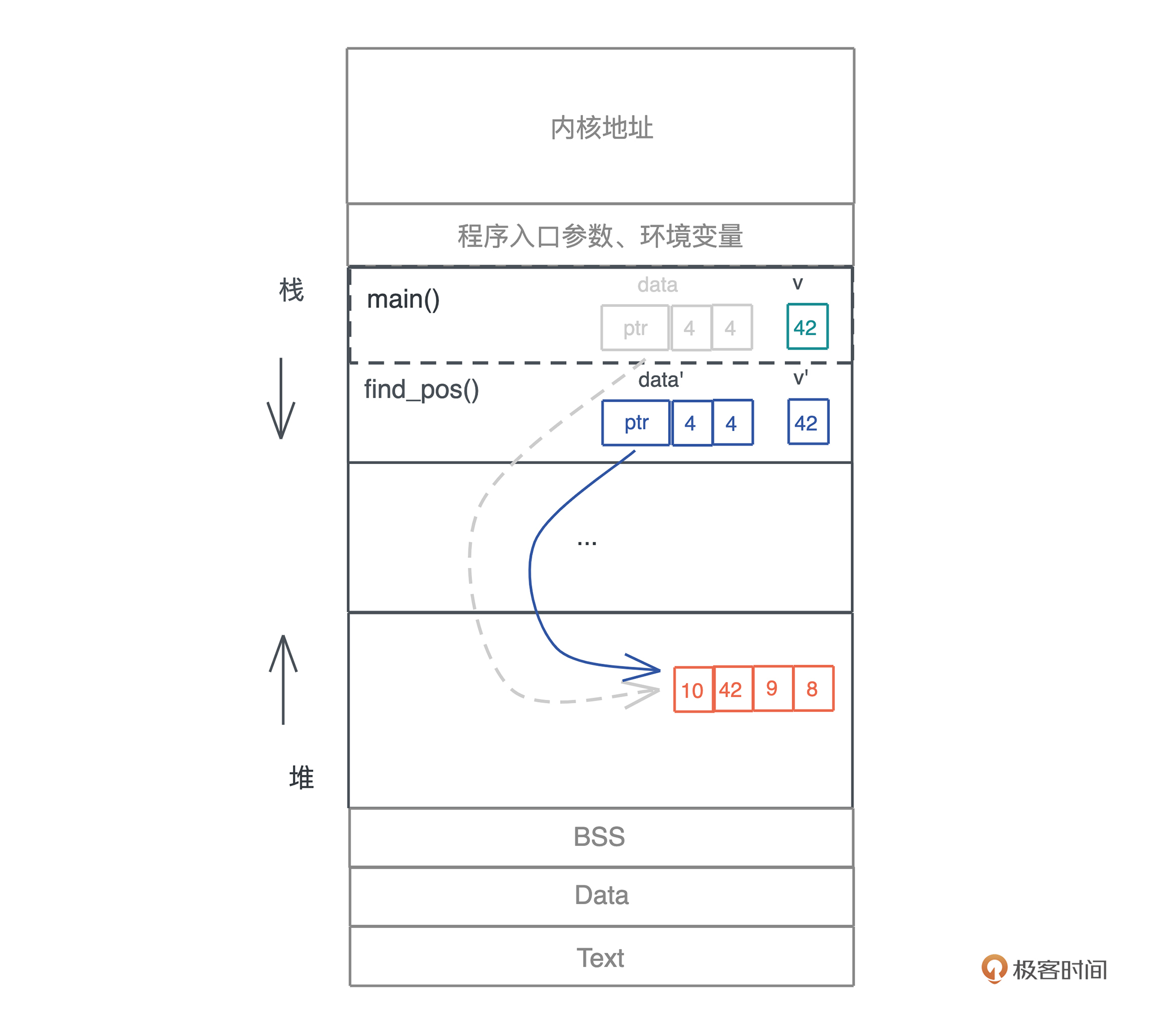
Move 语义
上面的例子说明 赋值或者传参会导致值 Move,所有权被转移,一旦所有权转移,之前的变量就不能访问。
所以如果此时想在 main() 使用 data 则会报错,Rust 考虑到了这一点,提供了两种方案:
- 如果你不希望值的所有权被转移,在 Move 语义外,Rust 提供了 Copy 语义。如果一个数据结构实现了 Copy trait,那么它就会使用 Copy 语义。这样,在你赋值或者传参时,值会自动按位拷贝(浅拷贝)。
- 如果你不希望值的所有权被转移,又无法使用 Copy 语义,那你可以“借用”数据,也就是 borrow
Copy 语义
符合 Copy 语义的类型,在赋值或者传参时,值会自动按位拷贝(浅拷贝)。
也就是说,当需要移动一个值,如果值的类型实现了 Copy trait,就会自动使用 Copy 语义进行拷贝,否则使用 Move 语义进行移动。
Copy trait
1 | fn is_copy<T: Copy>() {} |
总结一下:
- 原生类型,包括函数、不可变引用和裸指针实现了 Copy;
- 数组和元组,如果其内部的数据结构实现了 Copy,那么它们也实现了 Copy;
- 可变引用没有实现 Copy;
- 非固定大小的数据结构,没有实现 Copy。
Borrow 语义
Borrow 语义允许一个值的所有权,在不发生转移的情况下,被其它上下文使用。就好像住酒店或者租房那样,旅客 / 租客只有房间的临时使用权,但没有它的所有权(默认情况下,Rust 的借用都是只读的)。另外,Borrow 语义通过引用语法(& 或者 &mut)来实现。
只读借用
在其他语言中,函数传参有两种方式:值传递(pass-by-value)和引用传递(pass-by-reference)(提问)
但 Rust 没有传引用的概念,Rust 所有的参数传递都是传值,不管是 Copy 还是 Move。所以在 Rust 中,你必须显式地把某个数据的引用,传给另一个函数。(就是copy栈上的值,不论栈上存的是“指针/地址”还是“值”。)
同时,Rust 的只读借用实现了 Copy trait,也就意味着引用的赋值、传参都会产生新的浅拷贝。
(这里可以分析一下这段代码)
1 | fn main() { |
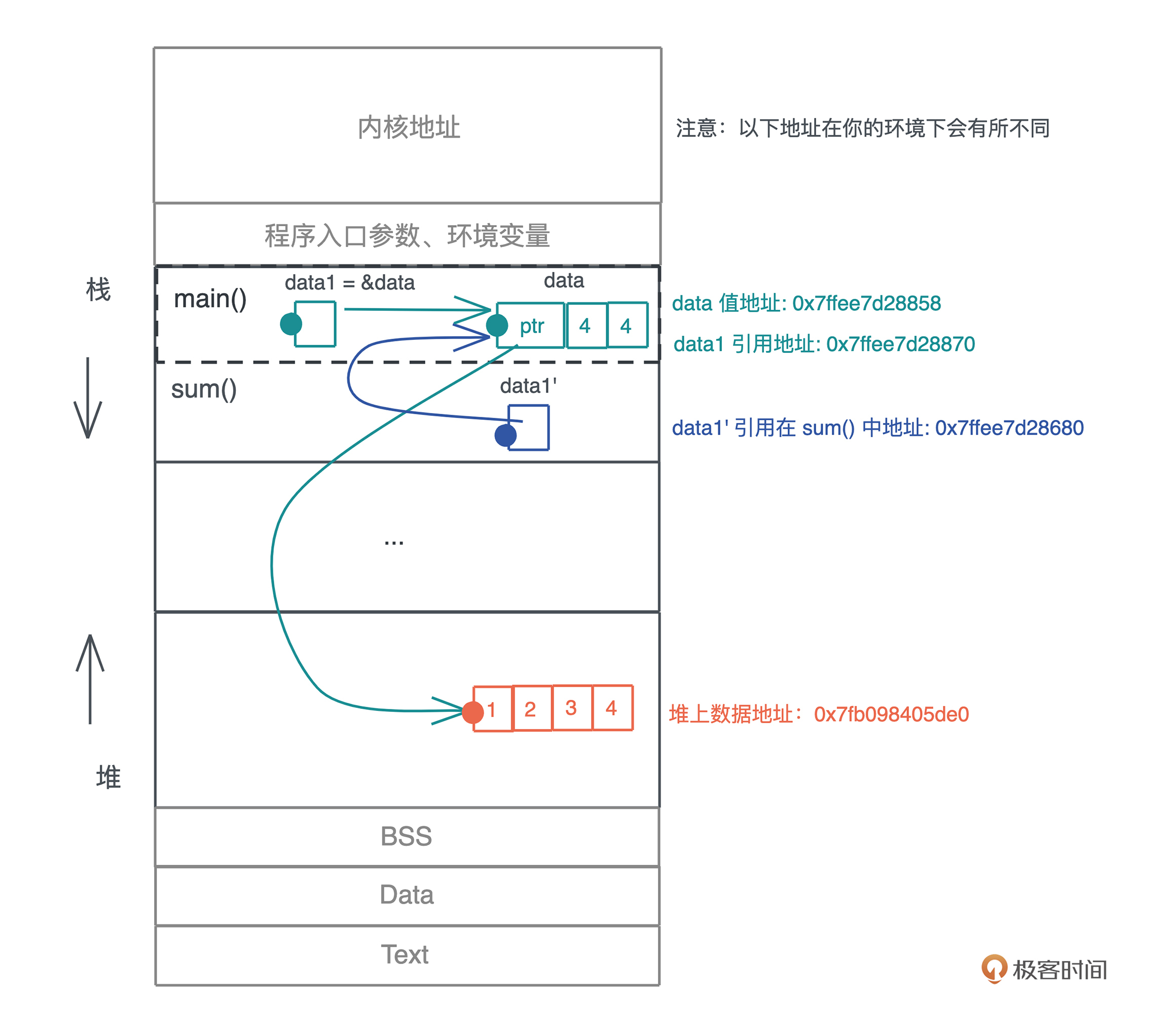
虽然 data 有很多只读引用指向它,但堆上的数据依旧只有 data 一个所有者,所以值的任意多个引用并不会影响所有权的唯一性。但是这样不就又回到我们之前在想极力避免的使用已释放内存(use after free)这样的内存安全问题吗?所以,我们对借用也要有约束。
借用的生命周期及其约束
借用不能超过(outlive)值的生存期
在上面的代码中,sum() 函数处在 main() 函数下一层调用栈中,它结束之后 main() 函数还会继续执行,所以在 main() 函数中定义的 data 生命周期要比 sum() 中对 data 的引用要长,这样不会有任何问题。
但如果是这样的代码呢?
1 | fn main() { |
显然,生命周期更长的 main() 函数变量 r ,引用了生命周期更短的 local_ref() 函数里的局部变量,这违背了有关引用的约束,所以 Rust 不允许这样的代码编译通过。
那么,如果我们在堆内存中,使用栈内存的引用,可以么?根据过去的开发经验,你也许会脱口而出:不行!因为堆内存的生命周期显然比栈内存要更长更灵活,这样做内存不安全。
我们写段代码试试看,把一个本地变量的引用存入一个可变数组中。从基础知识的学习中我们知道,可变数组存放在堆上,栈上只有一个胖指针指向它,所以这是一个典型的把栈上变量的引用存在堆上的例子(情况 2):
1 | fn main() { |
到这里,你是不是有点迷糊了,这三种情况,为什么同样是对栈内存的引用,怎么编译结果都不一样?
这三段代码看似错综复杂,但如果抓住了一个核心要素“在一个作用域下,同一时刻,一个值只能有一个所有者”,你会发现,其实很简单。
堆变量的生命周期不具备任意长短的灵活性,因为堆上内存的生死存亡,跟栈上的所有者牢牢绑定。而栈上内存的生命周期,又跟栈的生命周期相关,所以我们核心只需要关心调用栈的生命周期。
拓展– String vs &str in Rust
1 | fn main() { |
1 | let mut my_name = "Pascal".to_string(); |
1 | let mut my_name = "Pascal".to_string(); |
1 | my_name: String last_name: &str |
String is the dynamic heap string type, like Vec: use it when you need to own or modify your string data.
str is an immutable1 sequence of UTF-8 bytes of dynamic length somewhere in memory. Since the size is unknown, one can only handle it behind a pointer. This means that str most commonly2 appears as &str: a reference to some UTF-8 data, normally called a “string slice” or just a “slice”. A slice is just a view onto some data, and that data can be anywhere, e.g.
In static storage: a string literal
"foo"is a&'static str. The data is hardcoded into the executable and loaded into memory when the program runs.Inside a heap allocated
String:Stringdereferences to a&strview of theString‘s data.On the stack: e.g. the following creates a stack-allocated byte array, and then gets a view of that data as a
&str:1
2
3
4use std::str;
let x: &[u8] = &[b'a', b'b', b'c'];
let stack_str: &str = str::from_utf8(x).unwrap();
Move
正如在Memory safety in Rust - part 2[1]所展示的,把一个变量赋值给另一个变量会把所有权(ownership)转移给受让者:
1 | let v:Vec<i32> = Vec::new(); |
在上面的例子中,v被move到v1。但是move v意味着什么?要想理解这个问题,我们需要先来看一下一个Vec在内存中是如何布局的:
Vec不得不维护一个动态增长或收缩(shrinking)的缓冲区(buffer)。这个缓冲区被分配在堆上,包含Vec里真正的元素。此外,Vec还在栈上有一个小的对象。这个对象包含某些内务信息:一个指向堆上缓冲区的指针(pointer) ,缓存区的容量(capacity) 和长度(length) (比如,当前被填满的容量是多少)。
当变量v被move到v1时,栈上的对象被逐位拷贝(bitwise copy):
“
在前面的例子中,本质上发生的是一个浅拷贝(shallow copy)。这与C++形成了鲜明的对比,当一个向量被赋值给另一个变量时,C++会进行深拷贝(deep copy)。
堆上的缓冲区保持不变。这确实是一个move:现在v1负责释放缓冲区,v不能接触这个缓冲区。
1 | let v: Vec<i32> = Vec::new(); |
这个所有权的改变很好,因为如果v和v1都被允许访问,那么就有两个栈上的对象指向相同的堆缓冲区。
这种情况,应该由哪个对象释放缓冲区呢?因为这是不清晰的,所以Rust从根本上避免了这种情况的出现。
赋值不是唯一涉及到move的操作。当传递参数或者从函数返回的时候,值也会被move:
1 | let v: Vec<i32> = Vec::new(); |
或者被赋值给结构体或枚举的成员:
1 | struct Numbers { |
以上就是关于move的全部内容。下面让我们来看一下copy。
Copy
还记得上面的这个例子么?
1 | let v: Vec<i32> = Vec::new(); |
如果我们把变量v和v1的类型从Vec改为i32会发生什么?
1 | let v: i32 = 42; |
这几乎是相同的代码。为什么这次赋值没有把v move到v1呢?要想理解这个,我们需要再来看一下内存布局:
在这个例子中,值完全被包含在栈上。在堆上什么都没有拥有。这就是为什么v和v1都被允许访问是没有问题的——它们是完全独立的拷贝(copy)。
像这样没有拥有其他资源的类型且可以被逐位拷贝(bitwise copy)的类型被称为Copy类型。它们实现了Copy marker trait[2]。所有的基本类型,像整数,浮点数和字符都是Copy类型。结构体或枚举默认不是Copy但是你可以派生(derive)自一个Copy trait:
1 |
|
“
在派生语句中的
Clone是需要的,因为Copy的定义类似这样:pub trait Copy:Clone {}
为了能让#[derive(Copy, Clone)]正常工作,结构体或枚举的所有成员自身必须是Copy类型。例如,下面这样就无法正常工作:
1 | //error:the trait `Copy` may not be implemented for this type |
当然,你也可以手动实现Copy和Clone:
1 | struct Point { |
通常来讲,任何实现了Drop的类型都不能被Copy,因为Drop是被拥有其他资源的类型来实现的,且因此不能被简单地逐位拷贝。但是Copy类型应该是可以被拷贝的。因此,Drop和Copy不能很好地混合在一起使用。
以上就是关于copy的内容,下面是clone。
Clone
当一个值被move的时候,Rust做一个浅拷贝;但是如果你想像在C++里那样创建一个深拷贝该怎么办呢?要实现这个,这个类型必须首先实现Clone trait[3]。接着做一个深拷贝,客户端代码应该调用clone方法:
1 | let v: Vec<i32> = Vec::new(); |
在clone调用后,就产生了下面的内存布局:
由于是深拷贝,
v和v1可以自由独立地释放它们的堆缓冲区。
Clone方法不总是会创建一个深拷贝。类型可以以任意想要的方式自由实现clone,但是语义上,它应该足够接近复制一个对象的含义。例如,Rc和Arc取而代之的是增加了一个引用计数。