为什么每次在提交前都需要添加到暂存区呢?
如果有一百个相同的文件是会存储一百次吗?
本文将从Git的底层存储结构初窥Git的底层工作原理
Git保存版本的机制
1、集中式版本控制工具(如SVN)的文件管理机制:以文件变更列表的方式存储信息。
这类系统将它们保存的信息看作是一组基本文件(对应下图的Version1)和每个文件随时间逐步累积的差异(对应下图的其他Version),在文件管理的时候只保存当前版本相对于上一个版本的差异,这是一种增量式的版本控制。
2、Git 的文件管理机制:Git 把数据看作是小型文件系统的一组快照
每次提交更新时 Git 都会对当前的全部文件制作一个快照并保存这个快照的索引。为了高效,如果文件没有修改,Git 不再重新存储该文件,而是只保留一个链接指向之前存储的文件。
所以 Git 的工作方式可以称之为快照流。(这样的话就不用像集中式的 要一次次回退 才会去到历史版本 Git只需要切换到对应的版本指向的内容即可)
下图中Version2及其之后的实线框中的文件表示该版本的该文件相较于上个版本有变动,虚线框中的文件表示该版本的该文件相较于上一版本没有变动(只保存上一个版本的指针,而无需保存文件),这样根据当前版本的文件和指向上一版本的指针就可以找到该版本的所有文件的状态

可以看出 git的版本控制依赖的是每一次的commit 那怎么区分每次commit呢 就依靠每次提交都会生成一个独一无二的commitID
那么如何保证每次的 commitID 都是独一无二的呢? Git 使用了Hash算法来进行保证和文件验证
Hash算法
哈希是一个系列的加密算法,各个不同的哈希算法虽然加密强度不同,但是有以下几个共同点:
不管输入数据的数据量有多大,使用同一个哈希算法,得到的加密结果长度固定
哈希算法确定,输入数据确定,输出结果保证不变
哈希算法确定,输入数据有变化,输出结果一定有变化
哈希算法有很多种,如:MD5、SHA-1等。Git 底层采用的是 SHA-1 ,因为哈希算法可以被用来验证文件,Git 就是靠这种机制来从根本上保证数据完整性的
Git的实现原理
Git很好的解决了版本状态记录的问题,在此基础上实现了版本切换、差异比较、分支管理、分布式协作等等炫酷功能。那我们就一起通过实验看看Git数据库是如何工作的
这里我们会利用到下面几个命令:
- git init 用于创建一个空的git仓库,或重置一个已存在的git仓库
- git cat-file git底层命令,用于查看Git数据库中数据 (-t 查看类型 -p 查看内容)
- watch 可以将命令的输出结果输出到标准输出设备,多用于周期性执行命令/定时执行(这里我们结合tree 实时观察文件结构变化)
开始探索!
首先我们初始化一个仓库 并使用watch命令配合tree观察 .git文件
watch -n .5 tree .git
观察objects文件夹,这就是git数据库的存储位置。
然后新建文件
git add
观察 blob 文件
git commit
观察tree - 100个相同文件
观察commit 内容信息
commit对象能够帮你记录什么时间,由什么人,因为什么原因提交了一个新的版本,这个新的版本的父版本又是谁。
我们可以很清楚的看到,一个提交对象包含着所提交版本的树对象hash键值,author和commiter,以及修改和提交的时间,最后是本次提交的注释。
然后再新增文件 git commit
git log 观察commit文件
至此 我们就基本了解了树对象(tree object)和 提交对象(commit object)
利用树对象(tree object)解决文件名保存和文件组织问题
利用提交对象(commit object)记录版本间的时序关系和版本注释
看ppt 回顾一下上面的内容
commit保存的快照是什么呢
保存的是两个指针 一个指向上次的commit对象 另一个指向当前的这个tree
其实抽象的来看 这个快照就是保存了当前版本的所有文件 更准确的说是所有文件的引用
这也是我们可以迅速在各个版本间迭代的原因
一百个文件 上面也解释了 git只关注文件内容 那么也就只会有一个blob文件。
所以呢:
每次我们运行 git add 和 git commit 命令时,
Git 所做的实质工作是将被改写的文件保存为数据对象,更新暂存区,记录树对象,最后创建一个指明了顶层树对象和父提交的提交对象。 这三种主要的 Git 对象——数据对象、树对象、提交对象——最初均以单独文件的形式保存在 .git/objects 目录下。
但是到这里,我们对版本和数据对象的操作都是基于hash键值的,这些毫无直观含义的字符串让人很头疼,不会有人愿意一直急着最新提交对应的hash键值的。
那git是如何进行分支管理的呢
看ppt第一页
开始演示
git log
cat .git/refs/heads/master
Git checkout -b dev
再cat一下
再新建一个文件
git add
git commit -m
再cat一下前面那两个dev 和 master 发现是不一样的
对了 如果好奇head的话 可以cat一下
git log –oneline –graph
再看看tree
再看看ppt
merge啦
git switch master
git merge dev
Git的引用(references)与分支
Git的引用(references)保存在.git/refs目录下。git的引用类似于一个指针,它指向的是某一个hash键值。
Git 分支的本质:一个指向某一系列提交之首的指针或引用。
Git基本原理总结
Git的核心是它的对象数据库,其中保存着git的对象,其中最重要的是blob、tree和commit对象。
blob对象实现了对文件内容的记录,tree对象实现了对文件名、文件目录结构的记录,commit对象实现了对版本提交时间、版本作者、版本序列、版本说明等附加信息的记录。
这三类对象,完美实现了git的基础功能:对版本状态的记录。
Git引用是指向git对象hash键值的类似指针的文件。
通过Git引用,我们可以更加方便的定位到某一版本的提交。Git的branch、tags等功能都是基于Git引用实现的。
- merge时有冲突,合并时发生了什么
- merge时的diff对比怎么做到的
- revert时候发生了什么
- rebase的时候做了什么
- 贮藏是怎么做到了
- 树状结构仔细讲讲
git merge
merge基本原理
我们知道git 合并文件是以行为单位进行一行一行进行合并的,但是有些时候并不是两行内容不一样git就会报冲突,因为smart git 会帮我们自动帮我们进行取舍,分析出那个结果才是我们所期望的,如果smart git 都无法进行取舍时候才会报冲突,这个时候才需要我们进行人工干预。那git 是如何帮我们进行Smart 操作的呢?
二路合并
二路合并算法就是讲两个文件进行逐行对别,如果行内容不同就报冲突。

假设对于同一个文件,出现你和其他人一起修改,此时如果git来进行合并,git就懵逼了,因为Git既不敢得罪你(Mine),也不能得罪他们(Theirs) 无理无据,git只能让你自己搞了,但是这种情况太多了而且也没有必要…
三路合并
三路合并就是先找出一个基准,然后以基准为Base 进行合并,如果2个文件相对基准(base)都发生了改变 那git 就报冲突,然后让你人工决断。否则,git将取相对于基准(base)变化的那个为最终结果。
这样当git进行合并的时候,git就知道是其他人修改了,本地没有更改,git就会自动把最终结果变成如下:
如果换成下面的这样,就需要人工解决了:
递归三路合并原理
我们来看这样一个例子 现在如果我们要合并 ⑦(source) -> ⑥(destination):

简短描述下 如何会出现上面的图:
我们分别来看:
如果选择③作为公共祖先 根据最基本的三路合并,可以看到最终结果⑧ 将需要手动解决冲突 /foo.c = BC???

如果选择④作为公共祖先 根据最基本的三路合并,可以看到最终结果⑧ 将得到 /foo.c=C

Git 其实是这样进行合并的:
- git 既不是直接用③,也不是用④,而是将2个祖先进行合并成一个虚拟的 X /foo.c = B, 因为③ 和 ④ 公共祖先是 〇/foo.c = A
- git 用 X 做为 base 合并 ⑥ 和 ⑦ 结果就是 /foo.c = C
那什么又叫递归(recursive)合并呢 ? 我们合并 ⑥ 和 ⑦ 的时候,我们将其 2 个公共祖先③ 和 ④ 进行 merge 为 X ,在合并 ③ 和 ④时候 我们又需要找到 他们的公共祖先,此时可能又有多个公共祖先,我们又需要将他们先进行合并,如此就是递归了 也就是 recursive merge,如下:

合并策略(git merge)
当项目中包含多条功能分支时,有时就需要使用 git merge 命令,指定将某个分支的提交合并到当前分支。Git 中有两个合并策略:fast-forward 和 no-fast-forward。
fast-forward
fast-forward(–ff) 意为快进式合并,如果当前分支在合并分支前,没有做过额外提交。那么合并分支的过程不会产生的新的提交记录,而是直接将分支上的提交添加进来,这称为 fast-forward 合并。

很多时候我们在找2个修改集合X,Y 公共祖先的时候,会发现公共祖先就是他们中的一个,此时我们进行merge 的时候,就是Fast-Forward即可,不会产生一个新的Commit 用于merge X和Y 。看懂下面这个例子你就明白了:

当merge ② 和 ⑥时候 由于②是公共祖先,所以进行Fast-Forward 合并,直接指向⑥ 不用生成一个新的⑧进行merge了。
no-fast-forward
no-fast-forward(–no-ff)意为非快进式合并,fast-forward的场景很少遇到,基本是:在当前分支分离出子分支后(比如分支dev),后续会有其他分支合并进来的修改,而分离出的dev分支也做了修改。这个时候再使用git merge,就会触发 no-fast-forward 策略了。
在 no-fast-forward 策略下,Git 会在当前分支(active branch)额外创建一个新的 合并提交(merging commit)。这条提交记录既指向当前分支,又指向合并分支。
frevert & reset
在使用Git的过程中。某些时候,当你不小心改错了内容,或者错误地在本地commit了某些本不该提交的修改,我们就需要进行版本的回退。版本回退最常用的命令包括git reset和git revert。这两个命令允许我们在版本的历史之间穿梭。
Git reset
git reset 命令是用来将当前 branch 重置到另外一个 commit 的,这个动作可能同时影响到 index 以及 work directory。先举个例子,来一个感性的认识。现在有一个hotfix分支。
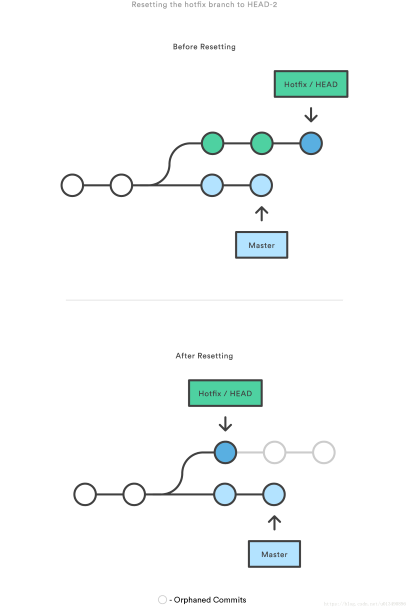
在执行下面这两条命令让 hotfix分支向后回退两个提交。上图就是命令执行前后,分支状态的对比。
1 | git checkout hotfix |
hotfix 分支末端的两个提交现在变成了孤儿提交。下次 Git 执行垃圾回收的时候,这两个提交会被删除。如果你的提交还没有共享给别人,可以用git reset撤销这些提交。因此git reset的使用场景是在本地版本需要回退时使用(前提是没有推送到远程库)。回退前,用git log可以查看提交历史,以便确定要回退到哪个版本;要重返未来,用git reflog查看命令历史,以便确定要回到未来的哪个版本。
如果你不想保留修改的文件,可以使用–hard参数直接回退到指定的commit,该参数会将HEAD指向该commit,并且工作区中的文件也会和该comit保持一致,该commit后的修改会被直接丢弃。
1 | $ git reset HEAD --hard |
git revert
Git revert用来撤销某次操作,此次操作之前和之后的commit和history都会保留,并且把这次撤销作为一次最新的提交。git revert是提交一个新的版本,将需要revert的版本的内容再反向修改回去,版本会递增,不影响之前提交的内容。虽然代码回退了,但是版本依然是向前的,所以,当你用revert回退之后,所有人pull之后,他们的代码也自动的回退了。
git revert和git reset都可以进行版本的回退,将工作区回退到历史的某个状态,二者有如下的区别:
git revert是用一次新的commit来回滚之前的commit,而git reset是直接删除指定的commit(并没有真正的删除,通过git reflog可以找回),这是二者最显著的区别;git reset是把HEAD向后移动了一下,而git revert是HEAD继续前进,只是新的commit的内容和要revert的内容正好相反,能够抵消要被revert的内容;
使用revert HEAD是撤销最近的一次提交,如果你最近一次提交是用revert命令产生的,那么你再执行一次,就相当于撤销了上次的撤销操作,换句话说,你连续执行两次revert HEAD命令,就跟没执行是一样的。
git revert 命令的好处就是不会丢掉别人的提交,即使你撤销后覆盖了别人的提交,他更新代码后,可以在本地用 reset 向前回滚,找到自己的代码,然后拉一下分支,再回来合并上去就可以找回被你覆盖的提交了。
通过git revert回退刚才的改动,或者修改代码后再次提交,但这样的话你的提交log会显得非常凌乱;
如果不想把中间过程的commit push到远程仓库,可以通过git reset 回退刚才的改动。
git cherry-pick
拣选会提取某次提交的补丁,之后尝试将其重新应用到当前分支上。 这种方式在你只想引入特性分支中的某个提交时很有用。
假设你的项目提交历史如下:
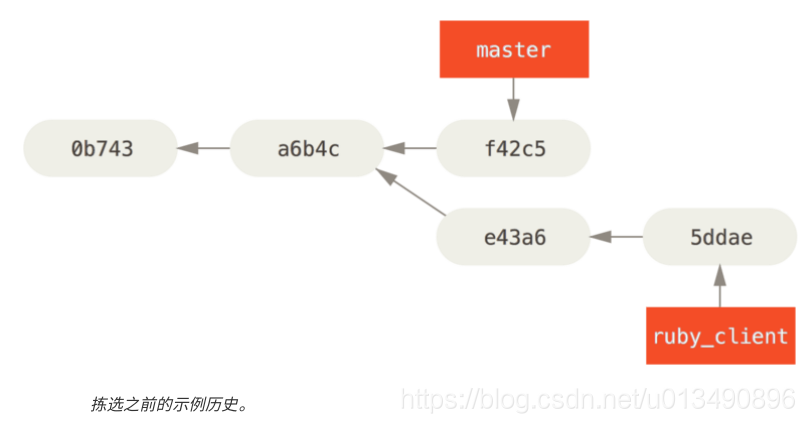
如果你希望将提交 e43a6 拉取到 master 分支,你可以运行
1 | # 当前在master |
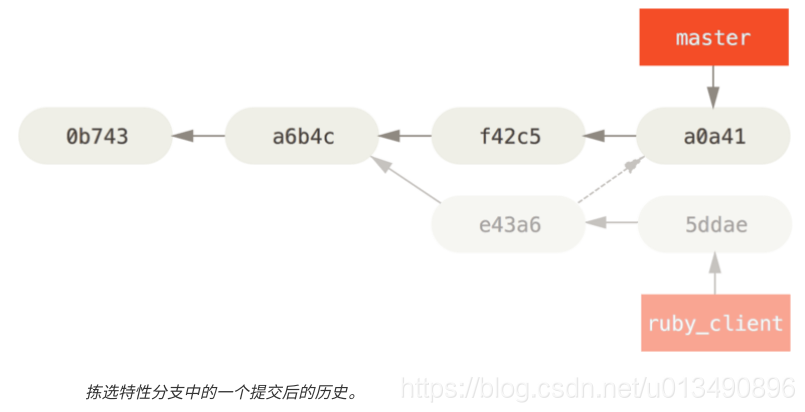
这样会拉取和 e43a6 相同的更改,但是因为应用的日期不同,你会得到一个新的提交 SHA-1 值。 现在你的历史会变成这样:
git rebase
git rebase 命令的文档描述是 Reapply commits on top of another base tip,从字面上理解是「在另一个基端之上重新应用提交」,这个定义听起来有点抽象,换个角度可以理解为「将分支的基础从一个提交改成另一个提交,使其看起来就像是从另一个提交中创建了分支一样」,如下图:
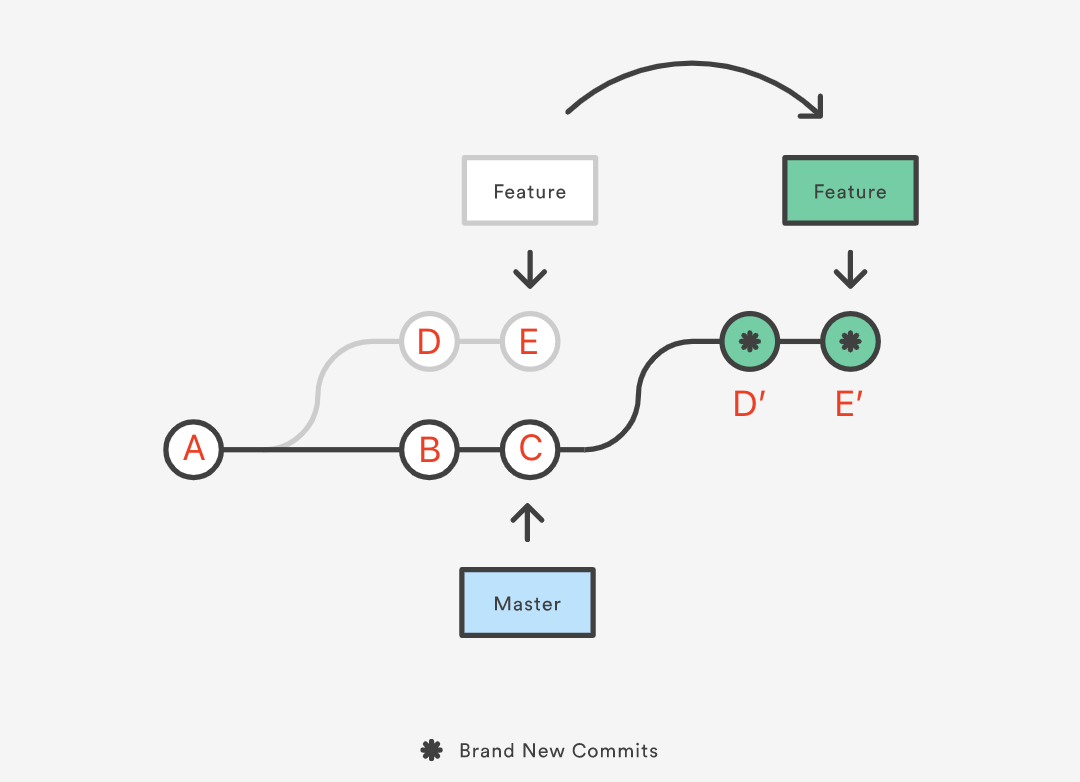
假设我们从 Master 的提交 A 创建了 Feature 分支进行新的功能开发,这时 A 就是 Feature 的基端。接着 Matser 新增了两个提交 B 和 C, Feature 新增了两个提交 D 和 E。现在我们出于某种原因,比如新功能的开发依赖 B、C 提交,需要将 Master 的两个新提交整合到 Feature 分支,为了保持提交历史的整洁,我们可以切换到 Feature 分支执行 rebase 操作:
1 | git rebase master |
rebase 的执行过程是首先找到这两个分支(即当前分支 Feature、 rebase 操作的目标基底分支 Master) 的最近共同祖先提交 A,然后对比当前分支相对于该祖先提交的历次提交(D 和 E),提取相应的修改并存为临时文件,然后将当前分支指向目标基底 Master 所指向的提交 C, 最后以此作为新的基端将之前另存为临时文件的修改依序应用。
我们也可以按上文理解成将 Feature 分支的基础从提交 A 改成了提交 C,看起来就像是从提交 C 创建了该分支,并提交了 D 和 E。但实际上这只是「看起来」,在内部 Git 复制了提交 D 和 E 的内容,创建新的提交 D’ 和 E’ 并将其应用到特定基础上(A→B→C)。尽管新的 Feature 分支和之前看起来是一样的,但它是由全新的提交组成的。
rebase 操作的实质是丢弃一些现有的提交,然后相应地新建一些内容一样但实际上不同的提交。
rebase 通常用于重写提交历史。下面的使用场景在大多数 Git 工作流中是十分常见的:
- 我们从
master分支拉取了一条feature分支在本地进行功能开发 - 远程的
master分支在之后又合并了一些新的提交 - 我们想在
feature分支集成master的最新更改
rebase 和 merge 的区别
以上场景同样可以使用 merge 来达成目的,但使用 rebase 可以使我们保持一个线性且更加整洁的提交历史。假设我们有如下分支:
1 | D---E feature |
现在我们将分别使用 merge 和 rebase,把 master 分支的 B、C 提交集成到 feature 分支,并在 feature 分支新增一个提交 F,然后再将 feature 分支合入 master ,最后对比两种方法所形成的提交历史的区别。
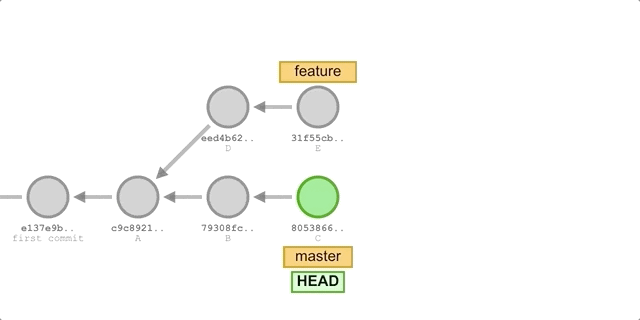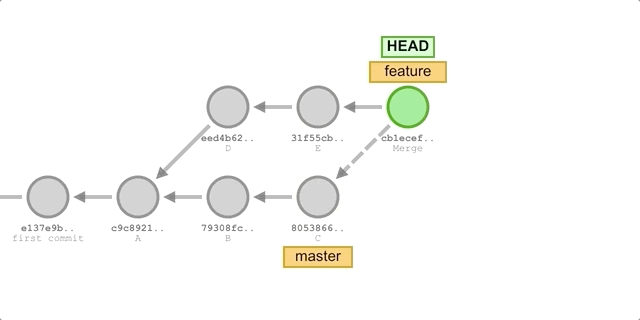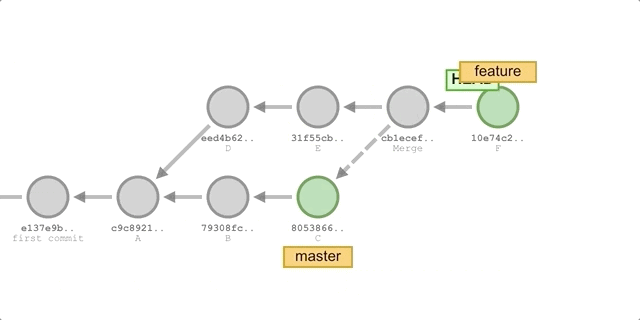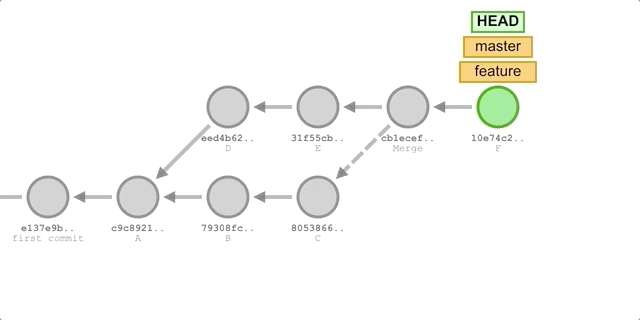
使用
merge- 切换到
feature分支:git checkout feature。 - 合并
master分支的更新:git merge master。 - 新增一个提交 F:
git add . && git commit -m "commit F"。 - 切回
master分支并执行快进合并:git chekcout master && git merge feature。
执行过程如下图所示:
我们将得到如下提交历史:
1
2
3
4
5
6
7
8
9* 6fa5484 (HEAD -> master, feature) commit F
* 875906b Merge branch 'master' into feature
|\
| | 5b05585 commit E
| | f5b0fc0 commit D
* * d017dff commit C
* * 9df916f commit B
|/
* cb932a6 commit A- 切换到
使用
rebase步骤与使用
merge基本相同,唯一的区别是第 2 步的命令替换成:git rebase master。执行过程如下图所示:
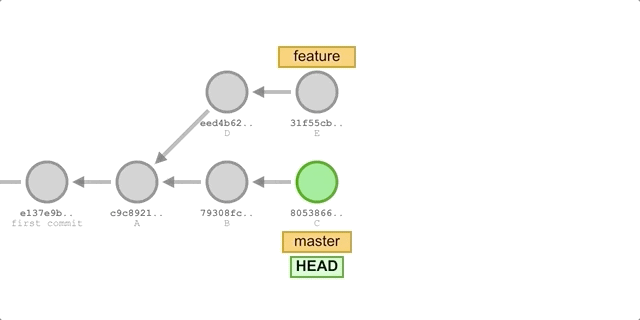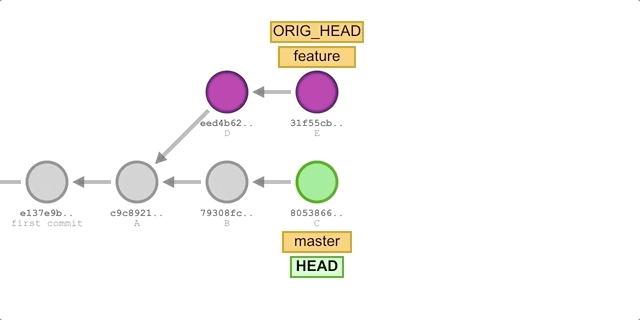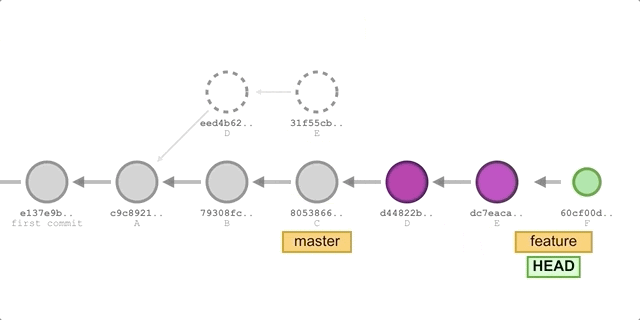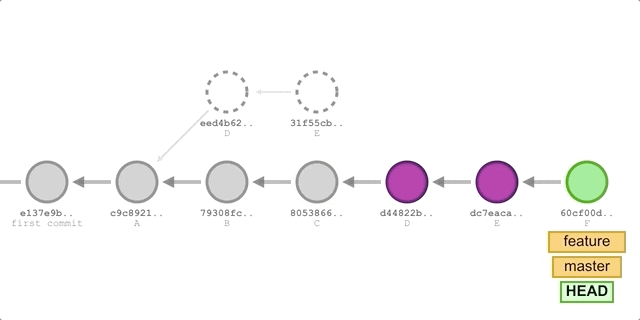
我们将得到如下提交历史:
1
2
3
4
5
6* 74199ce (HEAD -> master, feature) commit F
* e7c7111 commit E
* d9623b0 commit D
* 73deeed commit C
* c50221f commit B
* ef13725 commit A
可以看到,使用 rebase 方法形成的提交历史是完全线性的,同时相比 merge 方法少了一次 merge 提交,看上去更加整洁。
为什么要保持提交历史的整洁
一个看上更整洁的提交历史有什么好处?
- 满足某些者的洁癖。
- 当你因为某些 bug 需要回溯提交历史时,更容易定位到 bug 是从哪一个提交引入。尤其是当你需要通过
git bisect从几十上百个提交中排查 bug,或者有一些体量较大的功能分支需要频繁的从远程的主分支拉取更新时。
使用 rebase 来将远程的变更整合到本地仓库是一种更好的选择。用 merge 拉取远程变更的结果是,每次你想获取项目的最新进展时,都会有一个多余的 merge 提交。而使用 rebase 的结果更符合我们的本意:我想在其他人的已完成工作的基础上进行我的更改。
其他重写提交历史的方法
当我们仅仅只想修改最近的一次提交时,使用 git commit --amend 会更加方便。
它适用于以下场景:
- 我们刚刚完成了一次提交,但还没有推送到公共的分支。
- 突然发现上个提交还留了些小尾巴没有完成,比如一行忘记删除的注释或者一个很小的笔误,我们可以很快速的完成修改,但又不想再新增一个单独的提交。
- 或者我们只是觉得上一次提交的提交信息写的不够好,想做一些修改。
这时候我们可以添加新增的修改(或跳过),使用 git commit --amend 命令执行提交,执行后会进入一个新的编辑器窗口,可以对上一次提交的提交信息进行修改,保存后就会将所做的这些更改应用到上一次提交。
如果我们已经将上一次提交推送到了远程的分支,现在再执行推送将会提示出错并被拒绝,在确保该分支不是一个公共分支的前提下,我们可以使用 git push --force 强制推送。
注意与 rebase 一样,Git 在内部并不会真正地修改并替换上一个提交,而是创建了一个全新的提交并重新指向这个新的提交。
找回丢失的提交
在交互式模式下进行 rebase 并对提交执行 squash 或 drop 等命令后,会从分支的 git log 中直接删除提交。如果你不小心操作失误,会以为这些提交已经永久消失了而吓出一身冷汗。
但这些提交并没有真正地被删除,如上所说,Git 并不会修改(或删除)原来的提交,而是重新创建了一批新的提交,并将当前分支顶端指向了新提交。因此我们可以使用 git reflog 找到并且重新指向原来的提交来恢复它们,这会撤销整个 rebase。感谢 Git ,即使你执行 rebase 或者 commit --amend 等重写提交历史的操作,它也不会真正地丢失任何提交。
git reflog 命令
reflogs 是 Git 用来记录本地仓库分支顶端的更新的一种机制,它会记录所有分支顶端曾经指向过的提交,因此 reflogs 允许我们找到并切换到一个当前没有被任何分支或标签引用的提交。
每当分支顶端由于任何原因被更新(通过切换分支、拉取新的变更、重写历史或者添加新的提交),一条新的记录将被添加到 reflogs 中。如此一来,我们在本地所创建过的每一次提交都一定会被记录在 reflogs 中。即使在重写了提交历史之后, reflogs 也会包含关于分支的旧状态的信息,并允许我们在需要时恢复到该状态。
注意 reflogs 并不会永久保存,它有 90 天的过期时间。
还原提交历史
我们从上一个例子继续,假设我们想恢复 feature 分支在 rebase 之前的 A→B→C→D→E→F 提交历史,但这时候的 git log 中已经没有后面 5 个提交,所以需要从 reflogs 中寻找,运行 git reflog 结果如下:
1 | 64710dc (HEAD -> feature) HEAD@{0}: rebase (continue) (finish): returning to refs/heads/feature |
reflogs 完整的记录了我们切换分支并进行 rebase 的全过程,继续向下检索,我们找到了从 git log 中消失的提交 F:
1 | 74199ce HEAD@{15}: commit: commit F |
接下来我们通过 git reset 将 feature 分支的顶端重新指向原来的提交 F:
1 | # 我们想将工作区中的文件也一并还原,因此使用了--hard选项 |
再运行 git log 会发现一切又回到了从前:
1 | 74199cebdd34d107bb67b6da5533a2e405f4c330 (HEAD -> feature) commit F |